ハイパーメディア:RailsでWeb APIをつくるには、これが足りない (Hypermedia: The Missing Element to Building Sustainable Web APIs in Rails)
- はじめに
- Web API の 2 つの分類
- チェンジ (変化・変更)
- HTML の Web
- Hypermicrodata gem
- 結論: Web API は HTML Web アプリと同じように設計しよう
- おわりに
- 参考文献
- 著者について
はじめに
この記事は、RubyKaigi2014 での発表内容をまとめ、一部現状に即した加筆を行ったものです。
Web API の 2 つの分類
これからどんどん Web API をつくることが増えてくると思います。さて、Web API をつくるにも目的がいろいろあると思いますが、あなたのつくりたいのは「クモの巣 (Web)」 API ですか?「クモの糸 (“Thread”)」 API ですか?
| 「クモの巣」 API | ⇔ | 「クモの糸」 API |
|---|---|---|
| パブリック | プライベート | |
| 外部から使われる | 内部から使われる | |
| さまざまな目的のクライアント | SPA や専用のクライアント | |
| 予想しづらい、コントロールできない | 予想できる、コントロールできる |
この命名は筆者が行ったものですが、分類は目新しいものではありません1。また、これはどちらが良い悪いということではありません。またどちらかに必ず分かれるというわけでもなく、その中間という選択肢もあるでしょう。最近話題のマイクロサービスに適しているのは中間ぐらいかもしれません。
「Web を支える技術」の著者で知られる山本陽平氏は「API を RESTful にするかどうかは要件しだい」2 と述べています。クモの巣 API を作るか、クモの糸 API を作るか、も要件しだいです。どのような API を作るかによって、適切な構造や作り方は変わってきます。
今回はその中で、どちらかというとクモの巣 API、つまりパブリックでさまざまなクライアントが使い、どう使われるかをコントロールしづらいような Web API をうまく作るには、という話を進めていきます。
チェンジ (変化・変更)
変化は避けられない
ビジネスは変化します。サービスやソフトウェアも変化します。周りの状況が変化するというのもありますし、進化するにも変化が必要です。変化というものは避けられないわけです。Web API もその変化に適応しなければなりません。
私たちが Web API をつくる上での 1 つの目標は「変化に適応できる Web API」をつくること、といえます。
2 種類のチェンジ
変化、変更は大まかには 2 種類に分けられます。
| Breaking Change 「壊す変更」 | Non-Breaking Change 「壊さない変更」 |
|---|---|
| バージョンが変わる | バージョンが変わらない |
| 互換性がない | 互換性がある |
| クライアントが動かなくなる | クライアントがそのまま動く |
まとめて、左側を Breaking Change、右側を Non-Breaking Change と呼ぶことにします。
Breaking Change は非常に困ります。
クライアントのユーザは、クライアントが動かなくなるのでひどい目に遭います。開発者は、コードを書き直したり、デプロイし直さなければなりません。書き直すなんてすぐ、と思うかもしれませんが、もしクライアントが iOS アプリだったらどうなるでしょう。1〜2 週間も待たされるはめになります。その間クライアントは動かないままです。
仕様にミスがあったときなど、どうしても Breaking Change にしなければならないときもありますが、できるだけ Non-Breaking Change にしたいですね。 Non-Breaking Change のほうが、ユーザも、クライアント開発者も、API 提供側も幸せです。
Web API の変更を Non-Breaking Change にするためにはどうすればいいか、ということを考えるために、まずは Breaking Change が起こる原因について見ていきましょう。
API ドキュメンテーションからクライアントが作られる
既存のクライアントやライブラリは、どのように作られているでしょうか。
API の機能の一覧、この URL にこのパラメータを渡す、という使用法の説明 ( API ドキュメンテーション3 ) が Web サイトに載っています。開発者はそれを読んで、その通りにコードを書いてクライアントやライブラリを作る、ということが多いでしょう。
この場合、URL やパラメータが変わると、クライアントは壊れて動かなくなってしまいます。動かすためには、コードを書き直さなければなりません。
もう少し賢い方法として、API ドキュメンテーションをマシンリーダブルな形で提供している場合もあります。JSON SchemaやSwaggerなどです4。開発者はそこから、自動生成のソフトウェアを使ってクライアントやライブラリのコードを生成します。
でも、URL やパラメータに変更があるとやっぱり壊れてしまって、再生成が必要です。これでは根本的な解決になりません。人間が書かなくていいという点ではとても良いのですが。
なぜこうなってしまうのでしょうか。こうならないためにはどうすればいいのでしょう。
Breaking Change の原因
原理としては、API の変更がクライアントに伝わるようにすれば、クライアントは壊れないはずです。そのためには、1 ヶ所にまとまった API ドキュメンテーションからすべてをあらかじめ作るのではなく、API のそれぞれのレスポンスの中に個別のドキュメンテーションを埋め込み、クライアントは__実行時__にそれを読み取って判断すればよいのです。
URL やパラメータなどの情報5をクライアントが事前に持っていると、クライアントと API 実装との間に密結合ができてしまいます。密結合は Breaking Change につながります。Non-Breaking Change にするためには、密結合を避け、疎結合にする必要があります。
例:FizzBuzzaaS
疎結合とはどのようなものかを説明するために、エッセンスを抜き出した例として、FizzBuzzaaS を紹介します。これは Stephen Mizell 氏がハイパーメディアについて考えるためのブログ記事 Solving FizzBuzz with Hypermedia で作ったものです。
FizzBuzz とは、ある数字を与えたとき、それが 3 の倍数なら fizz、5 の倍数ならば buzz、両方 (つまり 15 の倍数) ならば fizzbuzz、いずれでもなければ数字をそのまま返す、というプログラムのことです。
FizzBuzzaaS とは、FizzBuzz as a Service つまり FizzBuzz の API ということです。この API の仕様は次の通りとします。
- サーバは与えられた 100 までの数の FizzBuzz を計算できる
- サーバは次の FizzBuzz が何になるか知っている
さて、クライアントが 1 から最後まで順番にすべての FizzBuzz を順番に取得したい場合、どのようにプログラムするでしょうか。
密結合なクライアント
(1..100).each do |i|
answer = HTTP.get("/v1/fizzbuzz?number=#{i}")
puts answer
end密結合なクライアントのコードのイメージです。自然なコードに見えるかもしれませんが、URL とパラメータがハードコードされています。ここで URL やパラメータ名が変わったら、このクライアントは動かなくなってしまいます。
また、1 から 100 までカウントアップするというサーバのロジックをクライアントでも同じように実装してしまっています。もしサーバが 1000 まで対応しても、クライアントは 100 までしか得ることができません。
疎結合なクライアント
root = HTTP.get_root
answer = root.link('first').follow
puts answer
while answer.link('next').present?
answer = answer.link('next').follow
puts answer
end疎結合なクライアントのイメージはこれです。 link メソッドがポイントです。
最初にこの API の入口にあたる root さえわかれば、次にそのレスポンスに含まれる first というリンクをたどって (リンクの URL を GET して)、最初の答えを得ます。たどった先には next というリンクが含まれていますから、それをたどれば次の答えが得られます。同様にリンクをたどっていけば順に FizzBuzz の値を最後まで得ることができます。
この FizzBuzz の例では、「次」の値がわかることが重要なことです。それが next というリンクで表現されているわけです。
このクライアントには URL はハードコードされていないし、サーバサイドのロジックも一切入っていません。つまり、URL やパラメータが変わってもそのまま動きますし、1000 まで FizzBuzz を返すようになればこのままですべての FizzBuzz を得ることができます。これが Non-Breaking Change のための疎結合な作り方です。
逆に言うと、このようなクライアントが作れるような API が望ましいわけです。
《コラム》埋め込みリソース
そんな、毎回リンクをたどっていたらリクエストが多くなりすぎる、と思うかもしれません。密結合の方法でも多くなるのは同じなのですが、疎結合ならもっとうまい方法があります。リンクの代わりに、リンク先のリソースをそのまま埋め込むのです。
{
"_links" : {
"division" : {
"href" : "/divisions/1"
}
},
"title" : "Manager",
"id" : 1,
"last_name" : "Cooper",
"first_name" : "Alice"
}↓
{
"division" : {
"name" : "Music",
"id" : 1,
"phone" : "008"
},
"title" : "Manager",
"id" : 1,
"last_name" : "Cooper",
"first_name" : "Alice"
}クライアントでは、リンクを GET してリソースを取得する操作と埋め込みリソースを取り出す操作を透過的に扱えるように実装します。すると、クライアントのコードは全く変えずに、サーバのレスポンスによってリクエスト数を減らすことができます。
Cookpad の Garage フレームワークは埋め込みリソースに対応しています。また、JSON 派生フォーマット (後述) の 1 つである HAL は、仕様として埋め込みリソースを定義しています。
「API コール」のメタファーは危険
ちょっと過激なことを言うと、API コール (API を呼び出す) というメタファーが危うい、ということが言えます。
クライアントが必要な URL やパラメータをあらかじめ用意して、API をコールする
このパラダイムは RPC と大差ありません。こういうイメージから離れましょう。クライアントが次に何をするかは、サーバからのレスポンスに含まれるリンクから選びます。こうすることで、変化に適応できるのです。これがハイパーメディアの考え方です。
HTML の Web
このようなクライアントとサーバは、想像上のものではありません。すでにたくさん存在します。それは HTML の Web の世界です。
Web アプリや Web サイトは変わり続けていますが、クライアントであるブラウザは壊れていません。HTML の Web の世界では、変更があってもなぜブラウザは壊れないのでしょう?
1 つの理由としては、HTML の中のデータの意味が緩いということがあります。HTML が表現する意味は「ヒューマンリーダブルなドキュメント」です。段落、リスト、表、セクション、……などがあります。 ブラウザは、HTML に書かれたデータの意味を厳密に解釈する必要はありませんし、レンダリングして人間にゆるく伝わればよいわけです。
もう 1 つ、重要な理由があります。
HTML とワークフロー
図 1 はブラウザの画面遷移図です。Web アプリは、ホームページを GET して、メッセージリストを GET して、……というワークフローを含んでいるといえます。もちろんワークフローは 1 種類ではなく、使う人が何をやりたいかによっても変わるので、正確にはワークフローの提案です。
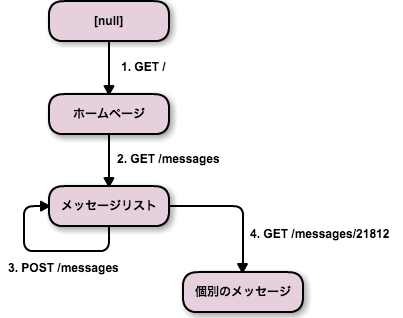
図 1 : メッセージアプリケーションの画面遷移図
ワークフローは、一連の画面遷移で表現されます。HTML ではそれはつまりリンクとフォームによって表されます。
図 2 は画面遷移図の中のメッセージリストの画面です。このように、それぞれの画面ごとに、次に何ができるかがリンクやフォームとして提示されます。これはメニューのようなものだといえます。ブラウザは、そしてブラウザを使う人間は、そのメニューから自分がやりたいことを選択して、次に進みます。このしくみこそがハイパーメディアです。
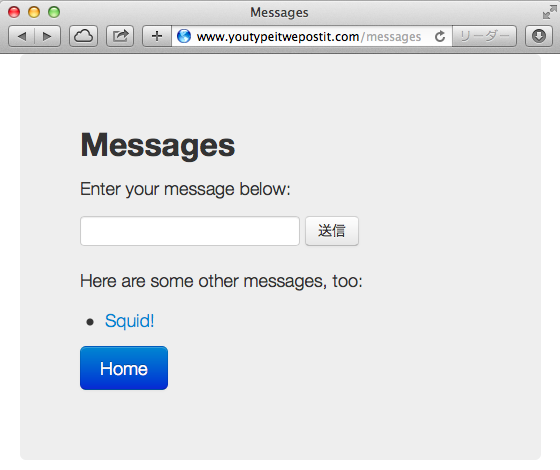
図 2 : メッセージアプリケーションのブラウザ画面
FizzBuzzaaS がやっていたのもこれと同じです。FizzBuzzaas では次へのリンクだけでしたが、この例は、メッセージへのリンクとメッセージを作るフォームという 2 つの選択肢を提示しています。
もし HTML にリンクがなかったら?
もし仮に、HTML にリンクが存在しなかったらどうなるでしょう?代わりに、メッセージ Web アプリを使うためのワークフローの手順書が用意されているとします。
メッセージ Web アプリ利用の手順書
1. アドレスバーに /messages と入力して GET
2. アドレスは /messages のまま、 title と body のパラメータに文字列をセットして POST
3. message-id を受け取って、アドレスバーに /messages/{message-id} と入力して GET
私たちはいちいちこんなことをしていられないので、URL やパラメータをハードコードしてこの通りにプログラミングして専用クライアントを作るでしょう。結果、サイトごとに専用クライアントが山のようにできて、そのクライアントは手順が変わると壊れるでしょう。今の Web API がやっているのはこういうことです。
Microdata と schema.org
さて、HTML にはあともう 1 点、役に立つところがあります。
HTML のクライアントはブラウザだけではありません。例えば検索エンジンのクローラというクライアントがあります。クローラはリンクをたどって HTML を集めるので、リンクによってうまく動くクライアントです。
そして、Google は検索結果にレストランのレーティングや、音楽のトラックリストを表示することがあります (リッチスニペット)。前節では、HTML には段落・リストやセクションなどの意味しか含まれていないと書きました。レストランタグとかミュージックタグはありませんよね。しかしクローラは、HTML のどの部分がデータで、そのデータの意味は何かということを認識しているということになります。どのようにやっているのでしょう?
その方法が、Microdata です。Microdata は、HTML のタグに特別な属性をつけることで、データの場所と名前を明示するというしくみです6。一般的には、SEO の手段として知られています。
<div itemscope itemtype="http://schema.org/Person">
My name is <span itemprop="name">Bob Smith</span>
but people call me <span itemprop="nickname">Smithy</span>.
Here is my home page:
<a href="http://www.example.com" itemprop="url">www.example.com</a>
I live in Albuquerque, NM and work as an <span itemprop="title">engineer</span>
at <span itemprop="affiliation">ACME Corp</span>.
</div>この例はある人物のプロフィールを書いた HTML ドキュメントです。itemscope という属性によって、アイテムと呼ばれるデータの位置を示します。itemtype によって、そのデータのタイプを示します。さらに itemprop 属性によって、アイテムの中のプロパティを示しています。
これはまさしく、ドキュメントの中に構造化データを埋め込むしくみです。HTML ドキュメントの構造が変わっても、タグが変わっても、データはそのまま変えないようにできます。例えば中にもう 1 つ div が入っても、プロパティは span でマークアップしていますが、リストにしても、データとしては同じです。
さらに、データを特定の URL に結びつけるという方法で、大まかな「データの意味」も表現できます。これによって、同じ意味のものについて、クライアントやサーバの処理の共通化や再利用がしやすくなります。ここでは http://schema.org/Person という URL を利用してこれが人のデータであることを表しています。同じようにして、これはレーティングであるとか、トラックリストであるということが表現できるわけですね。
schema.org は、Bing や Google などの検索エンジンが進めている、データの意味付けのための語彙のセットです。あらゆる語彙をカバーしているわけではありませんが、現在 700 種類以上のデータタイプが定義されています。ちなみにこれもリンクの一種なので、実際に URL にアクセスすると、この Person というデータタイプについての説明のドキュメントが得られます。
変えたときに壊れないためには、変わらない基盤としての標準と結びつければよいのです。schema.org は W3C や IETF の定めるような標準規格ではありませんが、Google, Yahoo, Bing などのメジャー検索エンジンが進めることから、ある種のフォーラム標準といえます。
schema.org の利用例:Gmail markup
Web API としての利用例とは少し違いますが、schema.org と Microdata (もしくは RDFa、JSON-LD) を利用してアクションなどのセマンティクスを表現し、それを利用している例があります。Gmail の受信トレイの右側に付くボタンです。GitHub からのメールなどに付いています。これは、メールに埋め込まれた schema.org のマークアップを Gmail が読み取って表示しています。
<html>
<body>
<div itemscope itemtype="http://schema.org/EmailMessage">
<div itemprop="action" itemscope itemtype="http://schema.org/SaveAction">
<meta itemprop="name" content="クーポンを保存"/>
<div itemprop="handler" itemscope itemtype="http://schema.org/HttpActionHandler">
<link itemprop="url" href="https://offers-everywhere.example.com/save?offerId=xyz789"/>
<link itemprop="method" href="http://schema.org/HttpRequestMethod/POST"/>
</div>
</div>
<p>
This a test for a One click action in Gmail.
</p>
<p itemprop="description">
$5 meal at Joe's Diner
</p>
</div>
</body>
</html>SaveAction の例

図 3 : Gmail に表示されたボタン
同様のしくみで Google Now のカードも表示されるようになっています。詳しい仕様はこちらを参照。
変化に適応するために必要な要素
ここまで見てきましたが、API を変化に適応できるようにするために、必要な要素を整理しましょう。
まず API として使えるためにはデータ構造、もっと単純にはどこがデータかがわからなければいけません。データの意味もあれば、クライアントの効率的な実装にさらに有利です。そして柔軟なワークフローを実現するためには、リンクとフォームが必要です。HTML にはリンクとフォームはありました。しかしデータとデータの意味がありませんでした。Microdata を追加することで、この 2 つが得られたわけです。
| データ | データの意味 | リンク | フォーム | |
|---|---|---|---|---|
| HTML | - | - | ✓ | ✓ |
| HTML+Microdata | ✓ | ✓ | ✓ | ✓ |
これだけ揃えば、HTML を Web API として使うことができます。実際、HTML から Microdata を抽出するための仕様 Microdata DOM API が定義されています。ブラウザに標準ではまだ実装されていませんが、JavaScript の実装が存在するので、すぐ使うことができます。または、Microdata を JSON に変換する仕様もいくつか定義されています7。
HTML の大きなアドバンテージは、リンクとフォームを最初から持っていることです。
var user = document.getItems('http://schema.org/Person')[0];
var name = user.properties['name'][0].itemValue;
alert('Hello ' + name + '!');Microdata DOM API の使用例
とはいえ、やっぱり HTML は冗長だし、クライアントからするとパースが面倒だしデータを抽出するライブラリも整備されていないので、JSON でやりたいと思うでしょう。ただ JSON にはリンクやフォームがない。これが HTML と JSON の本質的な違いです。API のフォーマットを JSON にするには、この足りないところを埋めればいいのです。
| データ | データの意味 | リンク | フォーム | |
|---|---|---|---|---|
| HTML+Microdata | ✓ | ✓ | ✓ | ✓ |
| JSON | ✓ | - | - | - |
JSON 派生フォーマット
リンクやフォームが表現できる JSON 派生のフォーマットがいくつかあります。用途に応じていずれかを使いましょう。
| データの意味 | リンク | フォーム | |
|---|---|---|---|
| JSON (application/json) |
- | - | - |
| JSON+Link ヘッダ8 | - | ✓ | - |
| HAL (application/hal+json) |
- | ✓ | - |
| JSON-LD (application/ld+json) |
✓ | ✓ | - |
| JSON-LD+Hydra | ✓ | ✓ | ✓ |
| UBER (application/vnd.amundsen-uber+json) |
- | ✓ | ✓ |
他にも、Hale, Siren, Collection+JSON, Mason, Verbose などさまざまなフォーマットがあります。
ほとんどは個人や企業が独自に作ったものですが、標準化が進んでいるものもいくつかあります。
- HAL: インターネットドラフト (期限切れ)
- JSON-LD: W3C 勧告
- Hydra: W3C コミュニティグループ
《コラム》 JSON でデータの意味を表す:「プロファイル」
http://schema.org/Person にアクセスすると、これが「人」を表すことを説明するドキュメントが得られます。このような「データの意味の説明」のことをプロファイルと呼びます。Microdata は、データとプロファイルを結びつけるしくみであるといえます。
JSON にプロファイルを組み合わせてデータの意味を表すには、JSON-LD コンテキストや ALPS が使えます。
JSON-LD コンテキスト
JSON 派生のフォーマットである JSON-LD は、データの名前を特定の URL に結びつけるJSON-LD コンテキストと呼ばれるしくみを定義しています。
JSON のデータから JSON-LD コンテキストにリンクすることによって、そのデータに対して意味を付加することができます。また、データ自体も JSON-LD なら、データの中にコンテキストを埋め込んで 1 つの JSON-LD ドキュメントにすることもできます。
ALPS (Application Level Profile Semantics)
Microdata や JSON-LD コンテキストはデータの名前を URL に結びつけます。しかしその URL にアクセスして得られるプロファイルがどのようなものかについては規定していません。
ALPS は、どんなデータフォーマットにも汎用的に適用可能で、さらにマシンリーダブルな形で利用できるようにしたプロファイルフォーマットです。“RESTful Web APIs”著者の Mike Amundsen 氏が作成・提案しています。2015 年 3 月現在、インターネットドラフトです。
Hypermicrodata gem
ここまでのことを踏まえて、JSON Web API をうまく作るための、ひとつの答えとして、Hypermicrodata gemを作りました。これは、HTML をサーバサイドで JSON に変換する gem です。
Microdata を JSON に変換する仕様があると書きましたが、それとは少し違います。せっかく HTML にリンクやフォームがあるのだから、Microdata だけではなくリンクやフォームも抜き出して変換するというのが特徴です。さらに、ベースの ALPS プロファイルを用意して、データの意味も表しやすい形で JSON ベースのフォーマットを生成します。
使い方
使い方は簡単です。まず使用する JSON フォーマットを /config/mime_types.rb に設定します。現在 HAL と UBER に対応しています。
Mime::Type.register 'application/vnd.amundsen-uber+json', :uberjson
# もしくは HAL を使う場合は
Mime::Type.register 'application/hal+json', :haljsonそして使用するコントローラでモジュールを include します。
class PeopleController < ApplicationController
include Hypermicrodata::Rails::HtmlBasedJsonRenderer
...
endあとは、Web アプリと同じように HTML テンプレートを書いて、Microdata でマークアップします。複数の itemscope がある場合、__main__要素もしくは__data-main-item__属性のものがルートノードとみなされます。
%main.person{itemscope: true, itemtype: 'http://schema.org/Person', itemid: person_url(@person)}
.media
.media-image.pull-left
= image_tag @person.picture_path, alt: '', itemprop: 'image'
.media-body
%h1.media-heading
%span{itemprop: 'name'}= @person.name
= link_to 'collection', people_path, rel: 'collection'URL に設定した拡張子をつけるか、Accept ヘッダにメディアタイプをつけてリクエストすると、JSON のレスポンスが得られます。
GET /people/1 HTTP/1.1
Host: www.example.com
Accept: application/vnd.amundsen-uber+json{
"image": "/assets/bob.png",
"name": "Bob Smith",
"isPartOf": "/people",
"_links": {
"self": { "href": "http://www.example.com/people/1" },
"type": { "href": "http://schema.org/Person" },
"collection": { "href": "/people" },
"profile": { "href": "/assets/person.alps" }
}
}Hypermicrodata gem を使用した Rails による設計手順
それでは、Rails とこの Hypermicrodata gem を使って、API の 4 ステップの設計手順を簡単な API を例に説明します。
- リソース設計
- 状態遷移図を描く
- データの名前を対応する URL に結びつける
- HTML テンプレート (Haml, Slim など) を書いて、Microdata でマークアップする (その後、必要なら schema.org 定義にないプロファイルと説明を書く)
1. リソース設計
まず最初はリソースの設計をします。リソースというのはモデルに対応していると思っている人もいるかもしれませんが、必ずしもそうではありません。リソースは Rails のルーティングで__resources :notes__と書くときの__notes__の部分のことです。ここにはコントローラ名を書きますから、リソースは Rails のコントローラに対応しています。
もちろん、コントローラ名とモデル名が一致する場合も多く、今回の例もそうです。この手順ではモデルとコントローラの基本的な部分までを設計します。
ER 図を描いてデータベースのテーブル設計をして、それに応じてモデル、コントローラを作りましょう。ここでは Note という非常に単純なメモを書く API を考えます。本文の text、そして公開されているという状態を持たせたいので、公開時間をあらわす published_at をつくります。ここは、Rails で Web アプリを作るのと同じやり方で作っていきましょう。
| カラム名 | 説明 | タイプ |
|---|---|---|
| text | note の内容のテキスト | text |
| published_at | note の公開時間 | datetime |
(id, created_at, updated_at は自動生成される)
$ rails g model Note text:text published_at:datetime2. 状態遷移図を描く
次に、サーバサイドのことをいったん忘れて、クライアントの体験の視点から状態遷移図を描きましょう。これが今までの API の設計ではあまりなかったところです。
「状態遷移図」と言っていますが、イメージは HTML のときの画面遷移図と同じです。API ですから、実際の画面がどうなるかは API を使うクライアントによって違いますが、設計の段階では Web ブラウザと同じイメージを持って作ってください。
ボックスがリソース (HTML でいうページ) を、矢印がリンクやフォームを表します。ボックスの中に書かれている名前が「リソースに含まれるデータの名前」、矢印に書かれている名前が「リンクの名前」になります。Rails の通常の resources で作った場合、リソースの集合である Collection と、その中の個別のリソースである Member の 2 種類のリソースができます。状態遷移図のテンプレートは図 4 のようになります。
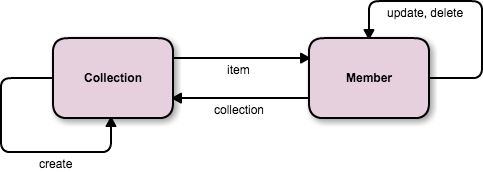
図 4 : Collection パターンの状態遷移図
このテンプレートから、データの名前を書き換えて、追加で必要な状態遷移の矢印を書き足していきます。リソースの状態を変える遷移である publish を追加します。さらに、最初のリソース設計から見落としがちなものとして、next, prev は忘れがちですが重要な例です。同様に first や last が必要なこともあるでしょう。
そして、この状態遷移図に入ってくる矢印が必要です。入口である「ホームページ」に相当するリソースもここでつくりましょう。ここでは独立したリソースにしましたが、単純な場合は Collection がホームページを兼ねてもかまいません。その場合は、最初の矢印は直接 Collection に入ります。こうしてできたものが図 5 です。
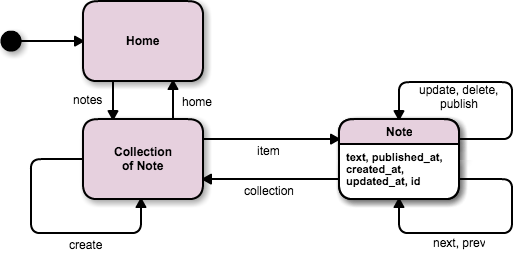
図 5 : Note API の状態遷移図
3. データとリンクの名前を対応する URL に結びつける
データの名前を、schema.org の語彙から対応する URL を探して当てはめましょう。これは必ず対応するものがあるとは限りません。しかし、できるだけ当てはめておくと、クライアントの処理の共通化に役立ちます。
| データの名前 | URL |
|---|---|
| Collection of Note | http://schema.org/ItemList |
| Note | http://schema.org/Article |
| - text | http://schema.org/articleBody |
| - published_at | http://schema.org/datePublished |
| - created_at | http://schema.org/dateCreated |
| - updated_at | http://schema.org/dateModified |
| - id | (各 note は個別の URL を持つので不要) |
| Home | http://schema.org/WebSite |
また、リンクの名前も対応する語彙があれば結びつけておきます。ただしリンクの名前はまだあまり選択肢がありません。schema.org の hasPart のように、プロパティとして存在すればそれを使いましょう。加えて、IANA のリンクリレーションは汎用的なリンクリレーションを定義しているので、あてはまるものがあれば取り入れましょう9。
create などの安全でない遷移 (フォーム) に対応する語彙は、schema.org では Action から探します。または、Activity Streams の語彙を使う方法もあります。IANA のリンクリレーションにはあまりありません。
| リンクの名前 | URL |
|---|---|
| item | IANA ‘item’ / http://schema.org/hasPart |
| collection | IANA ‘collection’ / http://schema.org/isPartOf |
| create | http://schema.org/AddAction / http://www.w3.org/ns/activitystreams#Add |
| update | http://schema.org/ReplaceAction / http://www.w3.org/ns/activitystreams#Update |
| delete | http://schema.org/DeleteAction / http://www.w3.org/ns/activitystreams#Delete |
| publish | http://schema.org/ActivateAction / http://www.w3.org/ns/activitystreams#Complete |
4. HTML テンプレートと Microdata を書く
好きなテンプレート言語で HTML テンプレートを書きます。状態遷移図の 1 つのボックスに対して 1 つのテンプレートが対応します。Note の Collection は index に対応します。
以下は、Haml でテンプレートを書いて、UBER という JSON ベースのフォーマットで出力した例です。UBER はリンクとフォームに対応しています。UBER の構造では、プロパティとリンクはどちらも data というリストの中に入ります。
%main{itemscope: true, itemtype: 'http://schema.org/ItemList', itemid: notes_url}
- @notes.each do |note|
= link_to note.text.truncate(20), note, rel: 'item', itemprop: 'hasPart'
= form_for Note.new do |f|
= f.text_field :text
= f.submit rel: 'create'{
"uber": {
"version": "1.0",
"data": [{
"url": "http://www.example.com/notes",
"name": "ItemList",
"data": [
{ "name": "hasPart", "rel": "item", "url": "/notes/1" },
{ "name": "hasPart", "rel": "item", "url": "/notes/2" },
{ "rel": "create", "url": "/notes", "action": "append",
"model": "note%5Btext%5D={text}" },
{ "rel": "profile", "url": "/assets/note.alps"}
]
}]
}
}Note は show に対応します。
%main{itemscope: true, itemtype: 'http://schema.org/Article', itemid: note_url(@note)}
%span{itemprop: 'articleBody'}= @note.text
%span{itemprop: 'datePublished'}= @note.published_at
%span{itemprop: 'dateCreated'}= @note.created_at
%span{itemprop: 'dateModified'}= @note.updated_at
= form_for @note, method: :put do |f|
= f.text_field :text
= f.submit rel: 'update'
= button_to 'Destroy', @note, method: :delete, rel: 'delete'
= button_to 'Publish', publish_note_path(@note), rel: 'publish' unless @note.published?
= link_to 'Next note', note_path(@note.next), rel: 'next' if @note.next
= link_to 'Prev note', note_path(@note.prev), rel: 'prev' if @note.prev
= link_to 'Collection of Note', notes_path, rel: 'collection', itemprop: 'isPartOf'{
"uber": {
"version": "1.0",
"data": [{
"url": "http://www.example.com/notes/1",
"name": "Article",
"data": [
{ "name": "articleBody", "value": "First note's text" },
{ "name": "datePublished", "value": null },
{ "name": "dateCreated", "value": "2014-09-11T12:00:31+09:00" },
{ "name": "dateModified", "value": "2014-09-11T12:00:31+09:00" },
{ "name": "isPartOf", "rel": "collection", "url": "/notes" },
{ "rel": "update", "url": "/notes/1", "action": "replace",
"model": "note%5Btext%5D={text}" },
{ "rel": "delete", "url": "/notes/1", "action": "remove" },
{ "rel": "publish", "url": "/notes/1/publish", "action": "append" },
{ "rel": "next", "url": "/notes/2" },
{ "rel": "profile", "url": "/assets/note.alps" }
]
}]
}
}ここで重要な点は、if や unless の条件文です。例えば、note が published な状態ならば、publish するボタンは出てきません。next がある場合だけ next へのリンクが現れます。prev も同様です。
リソースの状態に応じてリンクやフォームが変化することで、クライアントは自分が今何ができるかがわかります。これがハイパーメディアの 1 つの重要な特徴です。これは条件による動的なフローの変化です。このようにして、変化に適応することができるのです。
この設計手順の 3 つのメリット
メリット 1: DRY
これは HTML が必要な場合ですが、HTML テンプレートにはリンクやフォームを書くはずです。JSON のためにそれをもう一度書くことなく、そのまま再利用できます。同様に、Microdata のマークアップもそのまま利用できます。同じことを繰り返さない、これが DRY です。
二次的な効果として、HTML での Microdata は SEO も期待できます。将来的には JSON もクロールされて検索エンジンに乗ってくるでしょう。すでに JSON-LD というフォーマットであれば Google も対応しています。
さらに、もし JSON しか必要ない場合でもメリットがあります。
メリット 2: リンクとフォームを意識できる
JSON Web API を作るときには、どうしても状態遷移を見落としがちになります。API を HTML の Web アプリと同じように表現することで、状態遷移に着目して、適切にリンクやフォームを実装することができます。
また、HTML と同じように表現するということは、__form_for__を始めとする各種ヘルパーがそのまま使えるということも意味します。
メリット 3: 制約
この gem が行うことは、「HTML ドキュメントを Microdata でマークアップして、それを一定のルールで、フォーマットされた JSON に変換する」ということです。これはある種の制約だといえます。この制約が、よりよい設計の指針、ガイドになるのです。
制約は自由をもたらす (Constraints are liberating) by @dhh
従来の設計手順で作るときの注意点
もし HTML テンプレートを使わず、従来通り直接 JSON API のみを作る場合も、設計手順は先ほど説明したものとほとんど同じになります。
リンクとフォームを意識するために、状態遷移図を描きましょう。
疎結合を守るために、ビューテンプレートやリプレゼンターと呼ばれるものを使いましょう。例えば Jbuilder や RABL です。model.to_json を使うと、モデルの実装が外部に露出して、密結合ができてしまいます。 そして、リンクやフォームを持った JSON ベースのフォーマットを使いましょう。
それに加えて、schema.org のようなスタンダードの名前を使うとさらに良いですね。
(HTML の)Web サービスと Web API を分けて考えない by @yohei
結論: Web API は HTML Web アプリと同じように設計しよう
Web API は特別なものではありません。表現フォーマットが HTML か JSON かという違いがあるだけです。図を描いて状態遷移を意識することで、リンクやフォームの存在を忘れないようにしましょう。Web アプリと同じように、リンクやフォームをメニューとして提示し、クライアントはそこから選ぶことで目的を達成できるように設計しましょう。
そうすることで、変化に適応できる Web API を作ることができるのです。
おわりに
残念ながら、JSON のフォーマットやクライアント実装、それらのライブラリなど、まだデファクトスタンダードといえる手法がない部分も多くあります。しかし、Web 本来の考え方である REST の制約・原則に基いて考え、設計していけば、REST のメリットが得られ、より良いものができるはずです。その中でも、ハイパーメディアは最も重要な要素であり、変化に適応できる Web API への重要なステップです。
みなさん、ぜひよりよい、変化に適応できる Web API を作ってください。
参考文献
- L. Richardson & M. Amundsen “RESTful Web APIs” (O’Reilly)
- 山本陽平 “Web を支える技術” (技術評論社)
- Mike Amundsen “Designing for Reuse: Creating APIs for the Future”
- Mike Amundsen API Design Workshop 配布資料
- Zdenek Nemec “Robust Mobile Clients (v2)”
- Stephen Mizell “Solving FizzBuzz with Hypermedia”
- Mike Amundsen “Describing the Possible with ALPS”
- 山口 徹 “Web API デザインの鉄則” WEB+DB PRESS Vol.82 (技術評論社)
著者について
川村 徹 (@tkawa)
Rails ばかりやっているフリーランスプログラマ。RESTafarian。株式会社ソニックガーデン技術支援。Sendagaya.rb 共同主催、 RESTful Web APIs 読書会主催、RESTful#とは勉強会進行役。
-
The future of API design: The orchestration layer では、対象の分類として LSUDs (Large Set of Unknown Developers) と SSKDs (Small Set of Known Developers) が提唱され、話題になりました。その分類ともほとんど同じものです。 ↩
-
山本陽平 “WebAPI のこれまでとこれから” ↩
-
日本語では「API ドキュメント」と呼ぶことが多いかもしれません。「ドキュメント」という用語は、Web でアクセス可能な文書全般 ( JSON ドキュメントなど) に使うことができるので、説明・解説する資料の意味では「ドキュメンテーション」を使うことにします。 ↩
-
ここでは正確には、’'’インタフェース’'’を記述する API ドキュメンテーションをマシンリーダブルな形にしたもの。インタフェースを記述することから Web IDL (Interface Description Language) とも呼ばれます。インタフェースではなく API のデータの意味・語彙を記述したものもあり、こちらはプロファイルと呼ばれます。プロファイルは本文コラムでも説明しています。IDL とプロファイルについては Describing the Possible with ALPS も参照。 ↩
-
HTTP リクエストに含める URL、メソッド、ヘッダ、パラメータなどの情報。「RESTful Web APIs」ではプロトコルセマンティクスと呼びます。それに対して、API が提供するデータの意味をアプリケーションセマンティクスと呼び、こちらはクライアントが事前にある程度の情報を持っていなければなりません。 ↩
-
このようなしくみは RDF に始まり、Microformats で少し広まりましたが、class 属性を流用するなどの欠点がありました。それを解決しているのが Microdata や RDFa です。 ↩
-
WHATWG HTML Living Standard 5.5 Converting HTML to other formats や JSON-LD Relationship to Other Linked Data Formats など。 ↩
-
Link ヘッダはフォーマットではありませんが、レスポンスヘッダを使ってリンクを付加するシンプルな方法です。Link: http://www.example.com/data/2;rel=”next” のように使用できます。 ↩
-
IANA のリンクリレーションには、 http://schema.org/hasPart のような標準的な URL がありませんが、「リンクリレーション」を表現できる JSON フォーマット (リンクを表現できるフォーマットのほとんど) を使用する場合は、’item’のように名前だけでかまいません。 ↩