詳解! test-all 並列化
- はじめに
- 背景
- 実装
- 結果
- 実際に使用する
- 協力のおねがい
- 謝辞
- あとがき
- 著者について
書いた人: Shota Fukumori (@sora_h)
はじめに
こんにちは、リアル厨二1こと sora_h です。このたび、晴れて Ruby コミッタになりました。お祝いのメッセージをくださった皆さん、ありがとうございました。
本稿では、筆者が Ruby コミッタになるきっかけとなった、test-all の並列化について解説します。
対象読者
- Ruby の trunk を引っ張ってきて、ビルドまでできる人
- Ruby 本体の開発に興味がある人
(もしくは test-all を実行するのが趣味の人)
筆者環境について
本稿のコードは Mac OS X 10.6.6 で確認しています。
また、本稿の実装解説などは Ruby の r31140 2 のコードをベースとしています。 Ruby の開発が進むにつれ本稿の内容は古くなりますが、ご了承下さい。
背景
test-all とは
test-all とは、Ruby の組み込みクラスやメソッドや標準ライブラリがちゃんと動作するかを確認するための Make ターゲットです。
Ruby を ビルドした後、make test-all などで実行することができます。 実行すると test ディレクトリ内にあるテストファイル (test_*.rb) を探し、それらを読み込んで、機能が正常に動作するかのテストを実行します。
test-all の問題点と、その解決案
test-all は大量のテストを実行するために時間がかかります (原稿執筆時点でテストファイルが 620 以上!)。 筆者の環境ですと 5 分から 6 分、ひどいときは 15 分くらいかかります。 テストを実行している間は楽しくないので、やっぱり早く終わる方が良いですよね。
こうした不満を Ruby 札幌のチャットルームで言ったところ、並列化すると良いのではないかという返答が返ってきました。
sora_h: test-all を高速化させたい
mrkn: っ並列化
sora_h: 誰かやってるかな
mrkn: さぁ
これをきっかけに、筆者はプロセスをわけて複数のテストケースを並列に実行するパッチの作成にとりかかりました。
並列化の方針
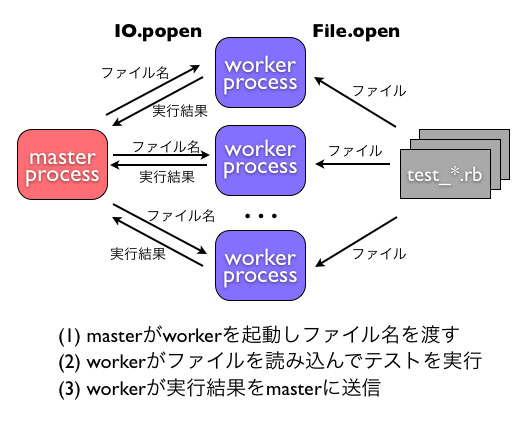
テストの実行を並列化するために、master プロセスと worker プロセスを導入しました (図1)。
- master プロセス (以下 master)
- 役割: worker を起動し、テストを実行するよう指示します。
- 動作: テストするファイル名を worker へ送信し、実行結果を受け取ります。
- ファイル: lib/test/unit.rb
- worker プロセス (以下 worker)
- 役割: 実際にテストを実行します。
- 動作: テストするファイル名を master から受け取り、それを require して中のテストケースを実行し、結果を master に返します。
- ファイル: lib/test/unit/parallel.rb
master と worker はパイプで繋がっており、後述するプロトコルで通信を行います。
また master は 1 つだけ起動され、worker は指定された数だけ起動されます。 最近のマルチコア CPU であれば、複数の worker を同時に走らせることでテストが並列に実行されるので、結果としてテスト時間が短縮されます。
図1: 並列動作の概要
パッチの提出
作成開始から約一週間でまともに動くようになったので、ruby-dev3 にパッチを投げたところ (ruby-dev:43226)、コミット権がもらえてコミッターになりました。
そこで r309394 でこのパッチをコミットし、その後リファクタリングを行ったり Windows でのバグを直したりして現在に至ります。
実装
さっそく実装を見ていきましょう。
今回解説するのは主要な処理の部分で、枝葉の部分 (例外処理など) は省いています。 ご了承ください。
master と worker のプロセス間通信プロトコル
前述したように、master と worker はパイプを利用してプロセス間通信を行っています。 ここでは、そのプロトコルで使われるコマンドとデータを説明します。
なお説明では以下の表記を使っています。
- 「database64」は base64 でエンコードされたデータを表します。
- 「datamarshal」は base64 でエンコードされた marshal 文字列を表します。
- 「dataplain」は平文の文字列データを表します。
master → worker
- loadpath arraymarshal
- ロードパスの差分です。一部のテストがロードパスを変更するのでそれの対策です。worker はこの配列をロードパスに追加します。
- run filenameplain typeplain
- ファイル名とテスト種別 (通常は「test」) を送信してテストの実行を指示します。
- quit
- worker を終了させます。worker はこれを受け取ると bye を送信して終了します。
worker → master
- ready
- ファイルの実行が終了し、ファイルの実行を受け入れ可能になった時に送信されます。
- okay
- ファイルの実行を開始する時に出力します。
- done resultmarshal
- テストケースの実行が 1 つ終わるごとにその結果を返します。結果は配列であり、テストメソッド数、テストアサーション数、error 数、failure 数、skip 数、ロードパスの差分、テストケース名をこの順で含んでいます。
- p stringbase64
- テストの出力 (「FooTest#test_bar: 1.0s = .」や実行経過を表す「….」など) を返します。
- after warningmarshal
- LoadError などテストケースの読み込み時に起こったエラーを伝えるときに使用されます。
- bye errormarshal
- 異常終了時の Exception を出力します。
- bye
- 正常終了時に送信されます。コマンドは上と同じですが、引数があれば異常終了、なければ正常終了を表します。
master の実装
master の実装は lib/test/unit.rb に含まれています。 つまり Ruby 標準のテスティングライブラリ自体に並列化機能を組み込んだことになります。
具体的には、lib/test/unit.rb に次のような変更を行いました。
- 並列実行用のコマンドラインオプションを追加
- master ではテストファイルを require しない
- worker の起動と停止
- worker との通信
- リトライ機能
以下、それぞれを説明します。
並列実行用のコマンドラインオプションを追加
lib/test/unit.rb:86 行目から抜粋
opts.on '--jobs-status [TYPE]', "Show status of jobs every file; Disabled when --jobs isn't specified." do |type|
options[:job_status] = (type && type.to_sym) || :normal
end
opts.on '-j N', '--jobs N', "Allow run tests with N jobs at once" do |a|
if /^t/ =~ a
options[:testing] = true # For testing
options[:parallel] = a[1..-1].to_i
else
options[:parallel] = a.to_i
end
end
opts.on '--no-retry', "Don't retry running testcase when --jobs specified" do
options[:no_retry] = true
end
opts.on '--ruby VAL', "Path to ruby; It'll have used at -j option" do |a|
options[:ruby] = a.split(/ /).reject(&:empty?)
end以下のようなコマンドラインオプションを追加しています。
- -j N, –jobs=N
- 最大 N つのテストケースの並列実行を許可します。指定しなければ worker などは生成せず、従来の動作をします。
- –jobs-status, –jobs-status=replace
- worker の状態、実行しているファイル名を随時表示します。–jobs-status=replace にするとエスケープシーケンスなどを用いて状態をターミナルの一番下のみに表示するようになり、ログには残らなくなります。
- –ruby=RUBY
- worker の起動に使う Ruby を指定します。Ruby には自分自身のパスを取得する確実でポータブルな方法が存在しないため、make コマンドからの起動時には起動オプションごと –ruby に渡しています。デフォルトでは RbConfig.ruby になっています。
- –no-retry
- 後述するリトライ機能を無効化します。
また、options[:ruby] は引数付きで渡されても大丈夫なように、split して配列で格納しています。
なお –jobs や -j オプションで worker でなく jobs という名称を使っているのは、make コマンドの -j オプションに合わせたためです。 本稿ではこのオプション名以外は worker で統一します。
master ではテストファイルを require しない
lib/test/unit.rb:214 行目から抜粋
begin
require path unless options[:parallel]
result = true
rescue LoadError
puts "#{f}: #{$!}"
endTest::Unit::RequireFiles モジュールで glob されたファイルを require していますが、並列化した場合は master で require する必要がなくなるため、無効化しています。
これによって実はテスト自体の開始が若干早くなり、また require を worker 側で行うので require が遅延評価かつ並列化されるため、テスト全体の実行時間が短縮されます。
worker の起動と停止
lib/test/unit.rb:314 行目から抜粋
# Array of workers.
@workers = @opts[:parallel].times.map {
worker = Worker.launch(@opts[:ruby],@args)
worker.hook(:dead) do |w,info|
after_worker_quit w
after_worker_down w, *info unless info.empty?
end
worker
}worker 抽象化クラスのクラスメソッド Worker.launch で worker を起動しています。
Worker クラスについては後述します。
また、worker の異常終了を処理するためにスレッドを起動して監視しています。
lib/test/unit.rb:405 行目から抜粋
watchdog = Thread.new do
while stat = Process.wait2
break if @interrupt # Break when interrupt
w = (@workers + @dead_workers).find{|x| stat[0] == x.pid }.dup
next unless w
unless w.status == :quit
# Worker down
w.dead(nil, stat[1].to_i)
end
end
end終了したプロセスの情報を返す Process.wait2 を呼んで子プロセスが終了するまでスレッドをブロックし、終了を監視しています。
もしプロセスの終了を感知した場合でも、^C などで終了しようとしている場合は @interrupt が真になるため、その場合はなにもせず break しています。
worker の配列から終了した Worker のオブジェクトを探し、もし意図した死亡でない場合はその worker プロセスを担当する Worker クラスのオブジェクトに死亡を伝えます。
テストが終了した際の worker の終了処理は ensure 文内で行っています。
lib/test/unit.rb:465 行目から抜粋
shutting_down = true
watchdog.kill if watchdogまずは監視用スレッドを終了させ、終了中を示すフラグを true にします。
@workers.each do |worker|
begin
timeout(1) do
worker.puts "quit"
end
rescue Errno::EPIPE
rescue Timeout::Error
end
worker.close
end次に全ての worker に quit コマンドを送信し終了を命じます。
begin
timeout(0.2*@workers.size) do
Process.waitall
end
rescue Timeout::Error
@workers.each do |worker|
begin
Process.kill(:KILL,worker.pid)
rescue Errno::ESRCH; end
end
endそして全ての子プロセスの終了を待ちます。タイムアウトした場合は SIGKILL で終了させます。
worker との通信
lib/test/unit.rb:420 行目から抜粋 (一部省略)
while _io = IO.select(@ios)[0]
break unless _io.each do |io|
break if @need_quit
worker = @workers_hash[io]出力があった worker の IO を IO.select を利用して取得し、_io 変数に代入しています。
そしてハッシュを使い Worker オブジェクトを取得しています。
break if @need_quitまた、ループの最後でもう出力を待ち受ける必要がない場合はループから抜けるようになっています。
そしてテストが全て終了すると ensure 文に入り、worker の終了、リトライなどを実行します。
case worker.read
when /^okay$/
worker.status = :running # ステータスを running に
when /^ready$/
worker.status = :ready # ステータスを ready に
if @tasks.empty?
break unless @workers.find{|x| x.status == :running }
else
worker.run(@tasks.shift, type)
endokay コマンドと ready コマンドの動作を説明します。
ready は、ファイルの実行が終了し再びコマンドの待ち受けに入ったことを意味します。 まだ実行していないファイルがあるときは Worker#run に渡して実行します。
まだ実行していないファイルもなく、かつ全ての worker が実行中でなければ、ループを抜けてファイナライズに入ります。
when /^done (.+?)$/
r = Marshal.load($1.unpack("m")[0])
result << r[0..1]
rep << {file: worker.real_file,
report: r[2], result: r[3], testcase: r[5]}
$:.push(*r[4]).uniq!done コマンドでは、worker から返されたテスト数 (test_foobar のようなメソッドの数) とアサーション数を結果に加えています。
また、リトライ用の情報を別の配列に加えています。
そしてロードパスに差分を加えてから、重複防止のため Array#uniq! しています。
when /^p (.+?)$/
print $1.unpack("m")[0]p コマンドはただ出力するだけですので unpack した文字列を print しています。
when /^after (.+?)$/
@warnings << Marshal.load($1.unpack("m")[0])after コマンドでは渡された例外を配列に加えているだけです。
LoadError などを受け取って、テストの結果出力の前にまとめて配列に入っている例外を出力します。
たとえば psych5 のテストファイルを require すると、libyaml6 がない環境では LoadError が出るため、それを見失わないよう最後に出力しています。
when /^bye (.+?)$/
after_worker_down worker, Marshal.load($1.unpack("m")[0])bye コマンドに base64 でエンコードされた文字列がついていた場合には異常終了を表しているため、異常終了時に呼ぶ after_worker_down メソッドを呼びます。 これが呼ばれると異常終了としてその例外を出力し、テスト全体の実行が中断されます。
when /^bye$/
if shutting_down
after_worker_quit worker
else
after_worker_down worker
endbye コマンドは quit コマンドの直後にも返されるため、意図して bye コマンドが返ってきた場合は after_worker_quit() 、意図していない終了の場合は after_worker_down() を呼んでいます。
after_worker_quit では IO を close したりなどのファイナライズを行っています。
リトライ機能
リトライ機能とは、worker で failure や error となったテストを master で実行し直す機能です。
残念ながら Ruby に付属するテストのすべてが並列動作に対応しているわけではなく、中には並列化に対応するのが困難なものもあります。 そのため、並列動作時に失敗したテストを、並列ではない状態で再実行させています。 これにより、テストを並列化に対応させる負担を減らしています。
再実行は master で行います。 これは、worker で実行すると失敗するテストも存在するので、なるべく従来の動作に合わせるためです。
lib/test/unit.rb:490 行目から抜粋
if @interrupt || @opts[:no_retry] || @need_quit
rep.each do |r|
report.push(*r[:report])
end
@errors += rep.map{|x| x[:result][0] }.inject(:+)
@failures += rep.map{|x| x[:result][1] }.inject(:+)
@skips += rep.map{|x| x[:result][2] }.inject(:+)もし ^C などでの途中中断や、–no-retry オプションが指定された場合はリトライをしません。
else
puts ""
puts "Retrying..."
puts ""
@options = @opts
rep.each do |r|
if r[:testcase] && r[:file] && !r[:report].empty?
require r[:file]
_run_suite(eval(r[:testcase]),type)
else
report.push(*r[:report])
@errors += r[:result][0]
@failures += r[:result][1]
@skips += r[:result][2]
end
end
endリトライするのは Module#name で名前が取得できたテストケースのみです。
Test::Unit::Runner::Worker クラス
Test::Unit::Runner::Worker クラス (以下 Worker クラス) で、worker プロセスを抽象化しています。
Worker クラスでは、以下の作業をメソッド化しています。
- worker プロセスの起動
- worker プロセスとの送受信
- worker プロセスへ run コマンドの送信
worker プロセスの起動
Worker.launch(ruby,args=[]) で worker プロセスを新たにひとつ起動して Worker クラスのオブジェクトを返します。 ruby に配列で ruby へのパスとその起動オプションを指定します。
lib/test/unit.rb:233 行目から抜粋
def self.launch(ruby,args=[])
io = IO.popen([*ruby,
"#{File.dirname(__FILE__)}/unit/parallel.rb",
*args], "rb+")
new(io: io, pid: io.pid, status: :waiting)
endやっていることは簡単で、IO.popen でプロセスを起動し、その情報を Worker.new に渡してオブジェクトを返しています。
worker プロセスとの送受信
Worker#puts と Worker#read が担当しています。
lib/test/unit.rb:250 行目から抜粋
def puts(*args)
@io.puts(*args)
endシンプルに IO#puts に渡しています。
lib/test/unit.rb:276 行目から抜粋
def read
res = (@status == :quit) ? @io.read : @io.gets
res && res.chomp
endこれはちょっと複雑です。もし worker が終了しているなら IO#read 、していないなら IO#gets を読んでいます。
そして返り値は nil か String#chomp された String かになっています。
worker プロセスへ run コマンドの送信
Worker#run(task,type) にファイル名とタイプを渡すことで run コマンドを送信してくれます。
lib/test/unit.rb:254 行目から抜粋
def run(task,type)
@file = File.basename(task).gsub(/\.rb/,"")
@real_file = task–jobs-status オプションの処理と done コマンド受信時の動作用に、ファイル名をインスタンス変数に保管しています。
begin
puts "loadpath #{[Marshal.dump($:-@loadpath)].pack("m").gsub("\n","")}"
@loadpath = $:.dupロードパスの差分を送信し、将来また差分を取るために現時点のロードパスを複製して保管しています。
puts "run #{task} #{type}"
@status = :preparerun コマンドを送信し、ステータスを prepare に変更しています。
rescue Errno::EPIPE
dead
rescue IOError
raise unless ["stream closed","closed stream"].include? $!.message
dead
end
end例外処理です。終了していた場合は dead メソッドを呼んで IO の close などをしています。
worker の実装
worker の実装は lib/test/unit/parallel.rb になります。 master は parallel.rb を worker として起動します。
parallel.rb は主に以下のことを行います。
- master からファイル名を受け取ったらそれを require して中のテストケースを実行
- テストケース実行時の出力を master に送信
以下、詳細です。
おまじない
lib/test/unit/parallel.rb:77 から
Signal.trap(:INT,"IGNORE")^C でテストを中断すると子プロセスにも SIGINT が伝播してしまいますが、master の管理外で勝手に worker が終了すると迷惑なので、無視するようにしています。
また lib/test/unit/parallel.rb:80 から抜粋
@stdout = increment_io(STDOUT)
@stdin = increment_io(STDIN)STDIN と STDOUT は一部のテストケースが改変するので、@stdin と @stdout に dup してバックアップしてあります。
master からのコマンド受付
lib/test/unit/parallel.rb:84 行目から抜粋
while buf = @stdin.gets
case buf.chomp
when /^loadpath (.+?)$/
@old_loadpath = $:.dup
$:.push(*Marshal.load($1.unpack("m")[0].force_encoding("ASCII-8BIT"))).uniq!ロードパスの差分を受け取ってロードパスに加えます。 このとき、重複防止のために Array#uniq! を呼んでいます。
@old_loadpath はテストケース実行後にロードパスの差分を取るために使用されます。
when /^run (.+?) (.+?)$/
@stdout.puts "okay"run コマンドを受け取ってまずは okay コマンドを返します。
@options = @opts.dup
suites = MiniTest::Unit::TestCase.test_suites追加されたテストケースを確認するために Minitest::Unit::TestCase.test_suites を保持しておきます。
Minitest::Unit::TestCase.test_suites は毎回別のオブジェクトを返すので、Object#dup する必要はありません。
begin
require $1
rescue LoadError
@stdout.puts "after #{[Marshal.dump([$1, $!])].pack("m").gsub("\n","")}"
@stdout.puts "ready"
next
endrequire して LoadError が起こった場合、after コマンドでその事を master に伝え、再度コマンド待ち受け状態に戻ります。 LoadError は、たとえば libyaml がないときに psych ライブラリのテストを require したときなどに起こります。
_run_suites MiniTest::Unit::TestCase.test_suites-suites, $2.to_sym
@stdout.puts "ready"問題がなければテストケースを渡して実行します。
実行が終わったら ready コマンドを送信し、コマンドの待ち受け状態に戻ります。
when /^quit$/
begin
@stdout.puts "bye"
rescue Errno::EPIPE; end
exitquit コマンドを受信した場合、bye コマンドを返し終了します。
テストの実行
_run_suite メソッドがテストケースを実行します。 本来のテストケースの実行に _run_suite が使われるので、orig_run_suite にリネームしています。
lib/test/unit/parallel.rb:27 から
def _run_suite(suite, type)
r = report.dup
orig_stdout = MiniTest::Unit.output
i,o = IO.pipe
MiniTest::Unit.output = oMiniTest::Unit のテスト結果出力先を保持し、IO.pipe にバイパスするように変更しています。
th = Thread.new do
begin
while buf = (self.verbose ? i.gets : i.read(5))
@stdout.puts "p #{[buf].pack("m").gsub("\n","")}"
end
rescue IOError
rescue Errno::EPIPE
end
endテスト実行中にその出力を取得し、master に送信するためのスレッドです。 -v が指定された場合は1行ごと、-v でない場合は 5 バイトごとに出力するようにしています。
e, f, s = @errors, @failures, @skips
result = orig_run_suite(suite, type)
MiniTest::Unit.output = orig_stdouterror と failure と skip の個数を、差分の取得に使うために保管してから、テストを実行します。
orig_run_suite はテストのメソッド数とアサーション数の配列を返してきます。
o.close
begin
th.join
rescue IOError
raise unless ["stream closed","closed stream"].include? $!.message
end
i.closeテスト結果の出力を master に通知するスレッドを停止させています。 o.close すると i に EOF が入るので、自然に終了するかまたは例外が発生するのを待ちます。
result << (report - r)
result << [@errors-e,@failures-f,@skips-s]
result << ($: - @old_loadpath)
result << suite.nameここでは error や failure のメッセージ、error と failure と skip の数、ロードパスの差分、テストケース名を result に挿入しています。
begin
@stdout.puts "done #{[Marshal.dump(result)].pack("m").gsub("\n","")}"
rescue Errno::EPIPE; end
return resultdone を出力して result を返します。
ensure
MiniTest::Unit.output = orig_stdout
o.close if o && !o.closed?
i.close if i && !i.closed?
endensure 文で元の出力先へ確実に戻し、IO.pipe で開いた IO オブジェクトを close しています。
test/* の並列実行への対応
前述したように、すべてのテストが並列動作に対応しているわけではありません。 一部のテストは並列で動かすと failure もしくは error となります。
うまく動作しないテストのうち、その原因が分かったものは並列でも正しく動作するよう修正しました。
以下に、うまく動作しなかったテストとその原因を紹介します。
test/ruby/test_signal.rb
ここではテストではなく test/unit を修正しています。
このテストでは have_fork? で fork が使えるかを調べるときに、Test::Unit::Runner の at_exit が実行されてしまって若干表示が崩れます。
そのため、at_exit 実行時にフラグを見て、true のときは実行しないように変更しました。
test/ruby/test_process.rb
このテストは STDIN と STDOUT を改変するため、並列で動作しませんでした。
そのため、Test::Unit::Worker 側で STDIN とSTDOUT を dup してバックアップを保持するように変更しました。
test/net/test_https.rb, test_http.rb
これらのテストでは同じ番号のポートを使っていたため、並列で動作しませんでした。
そのため、ポート番号を変更して並列動作時に重複しないようにしました7。
test/csv
このテストでは複数のテストケースが同じディレクトリを使っていて、他のテストケースが teardown でディレクトリを消去するためにエラーが発生していました。
そのため、テストケースごとにディレクトリ名を変更することで対処しました。
結果
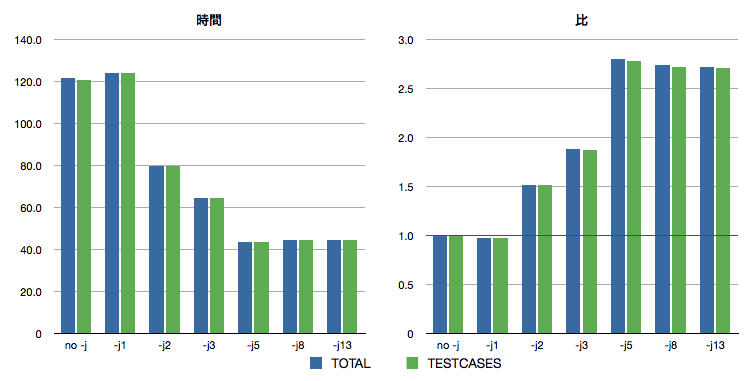
並列化の結果、どれくらいテスト全体が高速化したかのグラフを作成しました。
データは Ruby コミッタの一員である mrkn 氏に計測していただきました。 この場を借りてお礼を申し上げます。
環境
| OS | Mac OS X 10.6.6 |
|---|---|
| CPU | Intel Core i7 2.66 GHz (Dual Core) |
| Memory | 8GB 1067 MHz DDR3 |
データ
| -j | TOTAL | TESTCASES |
|---|---|---|
| no -j | 121.490313 | 120.7227436 |
| -j 1 | 124.2141424 | 124.1761476 |
| -j 2 | 79.8405502 | 79.79634 |
| -j 3 | 64.6310893333333 | 64.58236 |
| -j 5 | 43.4185176 | 43.36833 |
| -j 8 | 44.394446 | 44.3584944 |
| -j 13 | 44.6113974 | 44.5743406 |
ここで「no -j」は -j をつけずに実行した場合 (従来の動作)、「TOTAL」は time コマンドで計測した real の値、「TESTCASES」は test/unit が出力した Finished test… の値を表します。 また単位は秒です。
グラフ
図2. 時間と比率のグラフ
考察
並列動作させると、最大で約 2.7 倍の速度向上がみられました。 並列化によって高い効果が得られたことがわかります。
今回はデュアルコアの CPU で計測しましたが、worker 数が 5 のときに最大の効果が得られました。 デュアルコアの CPU でもこれほどの効果が得られるのですから、最近のクアッドコアあるいはそれ以上の CPU であれば、さらに効果が得られると思います。
実際に使用する
今回の並列化機能は Ruby の trunk ブランチに取り込まれているため、trunk を取得すれば使用できます。 Ruby の anonymous svn などから trunk を取得・ビルドし、以下のコマンドを入力してみてください (ビルド方法や trunk の取得方法などは割愛します)。
make TESTS='-v -j4' test-allこの場合なら、4 つの worker を起動して test-all を並列に実行します。
並列に実行されていることは、ログを見れば確認できます。 ログを見ると、通常はテストケースが 1 つずつ順番に実行されますが、-j オプションを有効にすると複数のテストケースがログに同時に現れるため、並列に実行されていることがわかります。
なお今回説明した並列化の機能は、test-all に限らず一般の Ruby プロジェクトでも使用できます。 現在 test/unit を使っていて複数のテストケースを実行しているなら、並列化のオプションを引数に加えることで、高速化の恩恵を受けることができるでしょう。
協力のおねがい
今回説明した機能は開発途中であり、一部のプラットフォームではまだ動作しません。動作しても安定しない場合があります。 その場合はログなどを添えて、Ruby バグトラッカー (Redmine) までご報告ください。 パッチもあるとなお良いです。
特に Windows では現時点でうまく動きません (test_process などでフリーズします)。 Windows で動くようにしてくれるパッチは歓迎いたします。
謝辞
mrkn 氏には、アドバイスやデータ計測などでご協力いただきました。 また、ruby コミッターの皆様にもアドバイス等を IRC で頂きました。 この場を借りてお礼申し上げます。ありがとうございました。
あとがき
短いですが、おおまかに parallel_test の実装を解説しました。
これからもこの機能がさらに安定して動作するように改良を続けていく所存です。 パッチなどは喜んで受け付けるので気軽にお願いします。
では。
2011年3月 こたつにて
著者について
Shota Fukumori (sora_h)。 小学六年から Rubyist、中二で最年少 Ruby コミッタ、この記事が公開されるころには中三の予定。 また「Ruby の C 実装を一番知らないコミッタ」3 代目を襲名。 iOS アプリなどを作っているのでよければ買ってください (http://itunes.apple.com/jp/app/bm-wifi-info/id410107488 とか)。
Twitter: @sora_h、Profile: http://sorah.cosmio.net/、Blog: http://codnote.net/
-
記事執筆時点。公開時点では厨三にバージョンアップしています。 ↩
-
編集部注:「r31140」とはリビジョン 31140 のことです。コミット日は 2011 年 3 月 21 日です。 ↩
-
編集部注:「ruby-dev」とは Ruby 開発者用メーリングリストのことです。 ↩
-
編集部注:「r30939」とはリビジョン 30939 のことです。コミット日は 2011 年 2 月 22 日。 ↩
-
編集部注:「psych」は Ruby 1.9.2 から標準搭載された YAML ライブラリです。利用するには libyaml が必要です。 ↩
-
編集部注:「libyaml」は C 言語で実装された YAML ライブラリです。その Ruby 用バインディングが psych です。 ↩
-
パッチを提出する前に IRC に書いていたら先に他の方にコミットされていたので、筆者の修正には入っていませんが。 ↩